🔍 Introduction And RAG Architecture
As Large Language Models (LLMs) have one major limitation is that —they don’t have real-time or domain-specific knowledge. This is where Retrieval-Augmented Generation (RAG) comes in . RAG is search the relevant content and send back the response to user quickly.
RAG combines information retrieval with text generation, dividing the content into chunks, enabling AI systems to deliver accurate, optimize, up-to-date, and context-aware responses.
👉 If you’re building modern GEN AI apps using LLMs, you must know RAG Architecture and how it works.
🧠 What is Retrieval-Augmented Generation (RAG)?
RAG is an AI architecture that:
- Retrieves relevant data from external sources and store in vector database.
- Augments the prompt with that data
- Uses an LLM to generate a better response
🏗️ RAG Architecture:
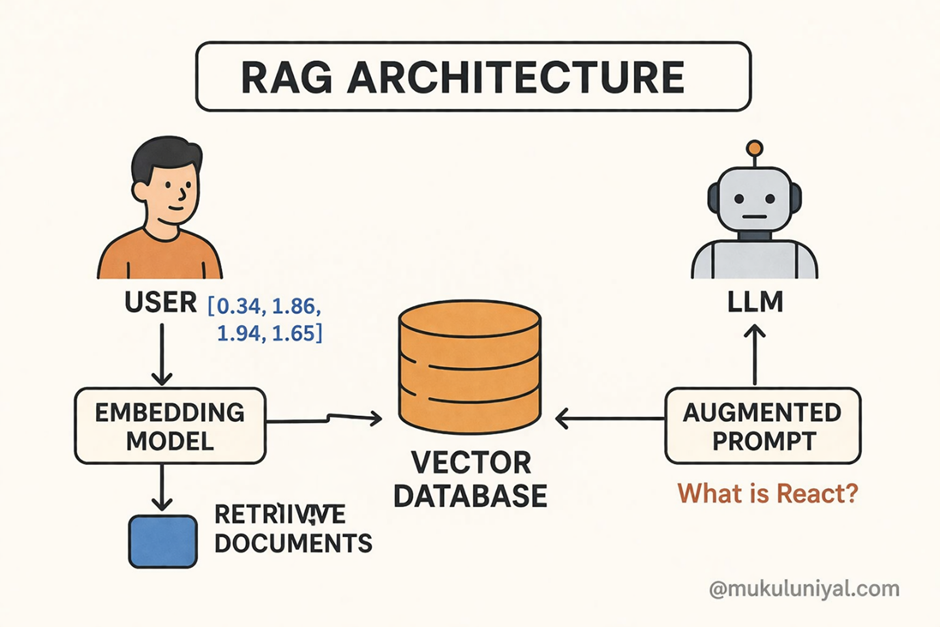
RAG consists of three core layers:
1. Data Layer (Knowledge Source)
- PDFs, APIs, databases, documents
- Structured or unstructured data
- External resource from web Or third party tools
2. Retrieval Layer
- Converts data into small chunks and then convert into embeddings
- Stores them into a vector database
- Finds relevant information using similarity search or semantic search
3. Generation Layer
- Uses LLM (like GPT) or any openAi provider( ollama, chatgpt5)
- Combines query + retrieved context
- Produces final output
How RAG Works (Step-by-Step Workflow):
Step 1: Data Ingestion & Chunking
- Large documents are split into smaller chunks or documents
- Each chunk or documents represents meaningful information
Step 2: Create Embedding
- Small documents or chunks are converted into vector embeddings
- Embedding are kind of vector representation
- Captures semantic meaning
Step 3: Vector Storage
- Embeddings are stored in vector databases like:
- FAISS DB
- Pinecone DB
- Weaviate DB
If there are already embedding stored then vector database does not store it to avoid duplicate documents
Step 4: User Query Processing
User query:
“Explain React prop forwarding”
- Query is also converted into embedding
Step 5: Semantic Retrieval
- Vector DB performs similarity search
- Retrieves top relevant chunks and gives the response to the user
Step 6: Prompt Augmentation
Context: [Top relevant chunks]
Question: Explain React prop forwarding
Step 7: LLM Response Generation
- LLM uses context + query
- Generates accurate answer
RAG Architecture Flow Diagram:
User Query
↓
Embedding Model
↓
Vector Search (Similarity Matching)
↓
Top-K Relevant Documents
↓
Prompt Augmentation
↓
LLM (Response Generation)
↓
Final Output
⚙️ Core Components of RAG
🔹 Embedding Model
- Converts text into vectors
- Example: OpenAI, HuggingFace
🔹 Vector Database
- Stores embeddings (pincone db)
- Enables fast semantic search
🔹 Retriever
- Fetches relevant documents for the relevant query
🔹 Generator (LLM)
- Produces responses for the human
🚀 Real-World Use Cases of RAG
1. AI Chatbots with Knowledge Base
- Customer support automation (chatBots)
- FAQ systems
2. Document Question Answering
- Legal, finance, healthcare documents
3. Enterprise Search Systems
- Internal company tools
- Knowledge discovery
4. AI Coding Assistants
- Retrieve code snippets
- Generate explanations
# Embed user query
query_embedding = embed("What is RAG architecture?")# Retrieve relevant docs
docs = vector_db.similarity_search(query_embedding)# Create augmented prompt
prompt = f"Context: {docs}\nQuestion: What is RAG?"# Generate response
answer = llm.generate(prompt)print(answer)here is above general code snippet for the beginning.
📊 RAG vs Traditional LLM
| Feature | Traditional LLM | RAG Architecture |
|---|---|---|
| Data Source | Static | Dynamic |
| Accuracy | Medium | High |
| Hallucination | High | Low |
| Real-time Data | No | Yes |
Best Practices for RAG
- Use optimal chunk size (200–500 tokens)
- Apply hybrid search (keyword + vector)
- Clean and preprocess data
- Monitor retrieval quality
- Cache frequent queries
🏁 Conclusion
Retrieval-Augmented Generation (RAG) is a powerful technique that enhances LLM capabilities by combining:
✔️ Retrieval (external knowledge)
✔️ Generation (LLM intelligence)
👉 It enables:
- Accurate and optimized AI systems
- Real-time knowledge source
- Scalable and fast GenAI applications